Persisting dbt artifacts with Github Actions
What are dbt Artifacts?
When building a dbt project, dbt generates a set of “artifacts” to the target subdirectory. These files include include metadata about the structure of the project, the model dependency graph, and more, all in JSON format.
Getting an up-to-date copy of the manifest.json from a production project is the primary prerequisite to enjoy features like state, deferral, and clone. There are lots of ways to do this, from manually compiling the production branch and saving the generated manifest, to having an automation store a copy in cloud storage like AWS or Google Cloud Storage.
In this post, I’ll explain how to persist production dbt artifacts in version control using Github Actions. This approach is motivated by (a) my lack of access to shared cloud storage at work, and (b) preference to avoid manually generating a production manifest every time I need one, and (c) my dbt Cloud project having >5,000 artifacts, making the manifest only accessible using the dbt Cloud API1.
State Comparison
A simple scenario to explain the usefulness of State:
- Update a dbt model’s sql in the local version of my dbt project
- Run
dbt compile, which generates thetarget/manifest.jsonartifact file - Obtain the
manifest.jsonfrom the production version of my dbt project, and copy it into my dbt project directory (i.e.,: the hard part, the purpose of this post) - Run
dbt run --select state:modified+ --state ., which compares my local manifest to the production manifest
This process allows dbt to identify the exact model that was modified, and runs it alongside its downstream dependencies. More crucially, this avoids wastefully running any unchanged models within the project. A massive efficiency benefit.
High-level GitHub Action flow
The overall flow after setting everything up will be:
- GitHub Action run is triggered by PR merge
- Check out the production branch, install dbt, configure a dbt profile, compile the project and generate dbt docs, which creates the artifacts
- Switch to a dedicated artifacts branch within the GitHub repo
- Copy the newly generated artifacts to the artifacts branch
Detailed Setup + Code Examples
This workflow assumes you have an existing dbt project, and access to a cloud data warehouse (i.e., Snowflake, Google BigQuery, etc), as well as access to create GitHub Environment Variables and Secrets within your GitHub’s repository settings.
1. Configuring the Workflow’s Setup Steps
This allows the workflow to interact with the cloud data warehouse, and run dbt commands (i.e., compile, run, generate docs)
My implementation uses two separate GitHub Actions: one to install dbt, and generate the profiles.yml file, and another to generate and persist the artifacts. In this example, I’ve used Google BigQuery2, and created dedicated Repository Secrets for this workflow (prefixed with CICD_)3.
2. Creating the Persist dbt Artifacts Action
This is the action that will be triggered on PR merges to the production branch. It depends on the dbt Setup action from the previous step, which handles the installation of dbt, and creation of the profiles.yml file.
The Results
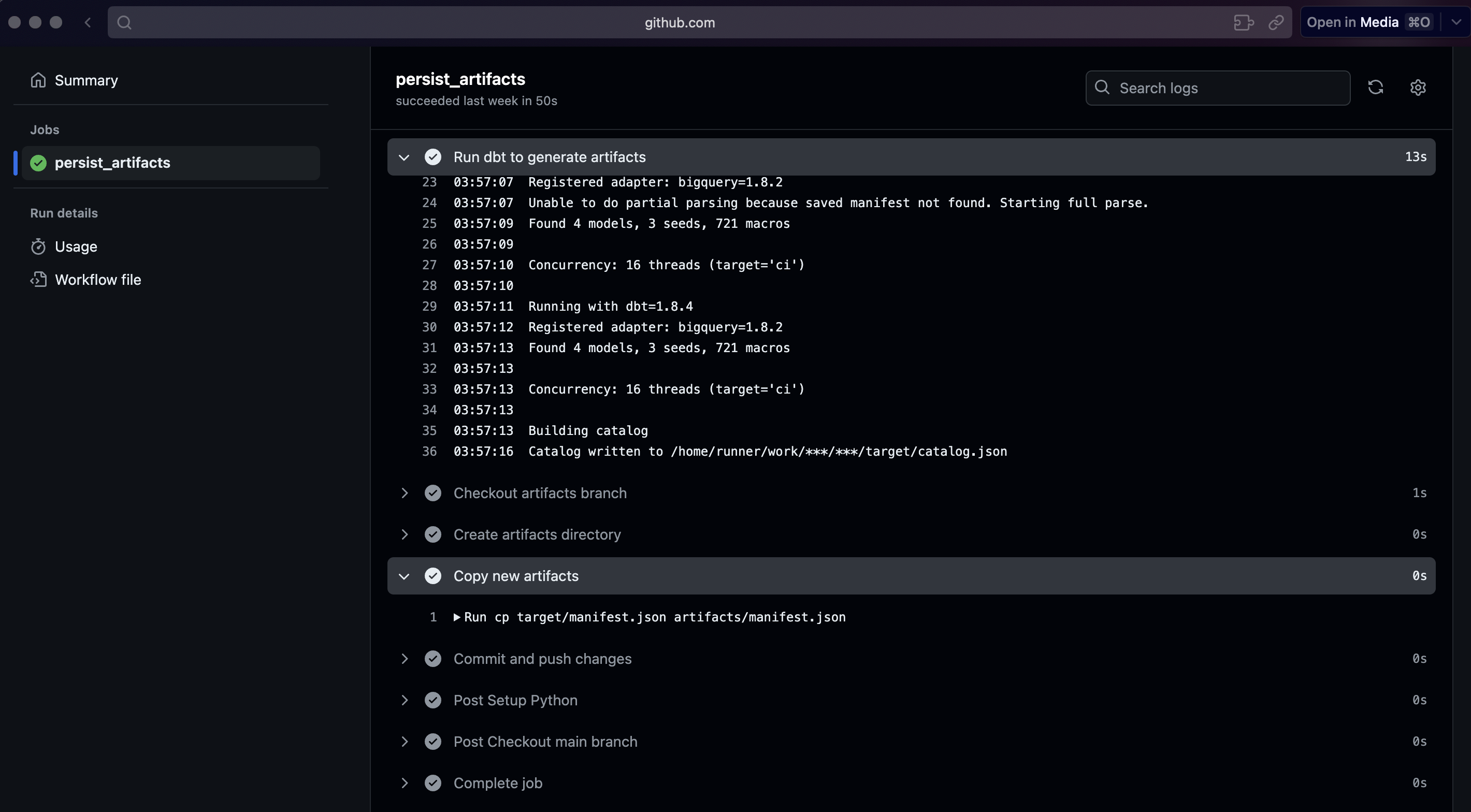
In my test project, the action looks like this:
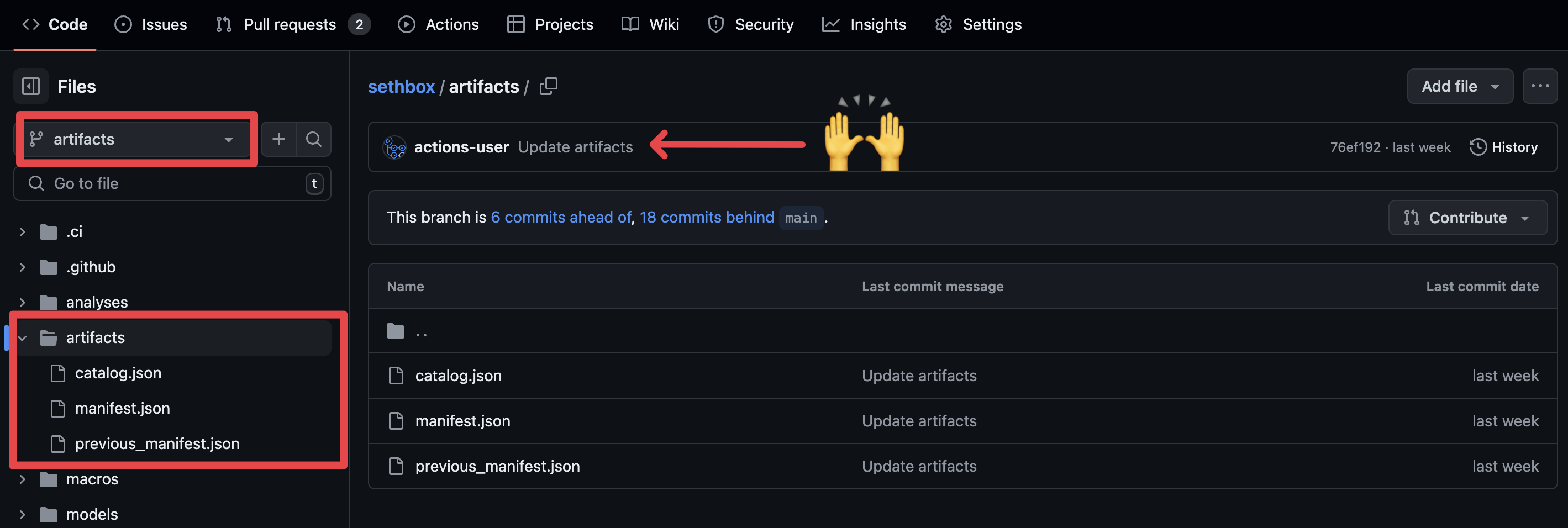
In my Github repo, I can easily grab my production manifest from here:
Future Extensions + Use Cases
The approach outlined above is just one of many ways to make dbt artifacts readily available, and may not be a good fit for every situation. By using GitHub Actions, you can automate the generation and storage of these artifacts without needing shared cloud storage or manual processes.
Having the artifacts available opens up a variety of powerful use cases, such as:
- Local Development: Easily download the manifest.json from the artifacts branch to take advantage of –defer, –state, and clone commands in your local environment.
- Persisting the Documentation Site: Host an up-to-date dbt documentation site using the latest production manifest and catalog, whether on a website hosting provider or a company intranet.
- CI/CD Enhancements: Power additional automations in your CI/CD pipeline, like deploying only modified models with state:modified, running write-audit-publish workflows, enabling Slim CI, or using custom diff-checking to streamline PR reviews.
-
It’s strange that dbt Cloud doesn’t prioritize exposing the JSON artifacts in the UI, and push (likely lower value) SQL artifacts beyond the 5,000 UI limit ↩
-
The specific profiles.yml parameters may also vary depending on your cloud provider. ↩
-
It’s essential to use secrets and/or environmental variables to prevent unauthorized access to your data warehouse. ↩